ZeroQuant
Background Knowledge
Quantization:
Idea 很简单,就是把模型的参数和运算从浮点数(FP32)映射到较低的精度,比如 INT8。这样做有两点好处。
- 减小了模型的大小,降低了内存开销。
- 一般来讲 CPU/GPU 做整形运算的速度都比浮点运算快,可以提升推理速度。
映射需要在降低模型精度的同时,维持量化之后参数分布与量化之前分布的同构性。其实线性映射就能做的很好了。
如下式所示,将原始值 \(r\) 映射到 \([q_{min},q_{max}]\)
\[S=\frac{r_{max}-r_{min}}{q_{max}-q_{min}}\] \[Z=-\frac{r_{min}}{S}+q_{min}\] \[q=\lfloor \frac{r}{S}+Z \rfloor\]
其中,\(S\) 用于缩放,\(Z\) 用于确定零点。我们需要做的就是确定 \(S,Z\)。
可以看出来,在量化的计算中 \(r_{range}=r_{max}-r_{min}\) 是至关重要的,量化的结果也是 range 敏感的。 在下面论文的讲解中我们也会用到这点。
模型量化的对象主要有 Weight, Activation, KV cache, Gradients。(量化的不仅是参数,还有运算)
Dequantization:
模型中一些算子支持低精度表示,那么很好,直接算就行了。
但还有一些算子需要高精度的输入输出(低精度导致很大的误差),就需要将 INT8 反量化为 FP32 再喂给算子计算。
\[r=S(q-Z)\]
这会引入误差。
PTQ(Post-training-quatization)
PTQ,即训练后量化,在模型完成训练之后对模型进行量化。
之前说过,量化需要确定 \(S,Z\),而 \(S,Z\) 又由 \(r_{max},r_{min}\) 确定,PTQ 通过选取少量校准数据估算出参数分布,来得到 \(r_{max},r_{min}\)。
以 FP32->INT8 的 PTQ 为例: 1. 训练出 FP32 的 baseline 模型。 2. Calibration:使用少量数据估算得到网络各层 weight/activation 的分布,得到 \(r_{max},r_{min}\) 3. 算出各层的 \(S,Z\)。 4. 用 \(S,Z\),将 FP32 的 baseline 量化得到 INT8。
PTQ 运算速度较快,但会损失一定精度。
QAT(Quantization-aware-training)
QAT,即量化感知训练。PTQ 中训练与量化是分开的,但是 QAT 通过在训练时加入伪量化算子,模拟量化带来的误差。
以 FP32->INT8 的 QAT 为例: 1. 训练出 FP32 的 baseline 模型。 2. 在 baseline model 中加入插入伪量化算子,在数据集上 finetune 得到的 QAT model。 3. 伪量化算子模拟推理时的量化,并保存 finetune 时得到的量化参数。 4. finetune 完成后,使用量化参数将 QAT model 量化为 INT8 model。
伪量化算子就是量化与反量化算子的结合,模拟 round 带来的误差,定义如下,
\[clamp(r;a,b)=min(max(x,a),b)\] \[s(a,b,n)=\frac{b-a}{n-1}\] \[q(r;a,b,n)=\lfloor\frac{clamp(r;a,b)-a}{s(a,b,n)}\rfloor s(a,b,n)+a\]
Challenge and Motivation
随着大模型的规模急剧增加,大模型的推理面对着两个问题,极高 GPU 内存占用和计算开销。
而解决这一问题的办法之一就是量化。其一可以降低模型的内存占用,其二可以提升模型的运算性能。
然而,为了弥补量化导致的精度损失,通常需要使用 QAT 技术,retrain 模型。这会带来几个问题:
- 训练用的数据往往不是公开的。
- 重新训练模型所需要很多计算资源。
- 耗时很久。
PTQ 技术就能解决这些问题,因为 PTQ
- 不需要训练数据。
- 极少的计算资源。
- 几乎不需要重新训练。
最近也有一些关于 PTQ 的量化工作,但是这些工作
- 只关注小规模的 CV 问题。
- 只局限于高精度量化(INT8/FP16),且只支持 BERT 模型。
- 不关注量化和反量化开销。(这是性能的重要组成部分)
- 对于极端量化(如 INT4)或更高的精度,通常使用知识蒸馏,导致额外的开销。
我们想要使用 PTQ 技术来解决上述问题,但是直接使用 PTQ 技术是不可行的,会导致 accuracy 的下降。
如图所示,图中 WXAY 代表 Weight 和 Activation 的量化精度。
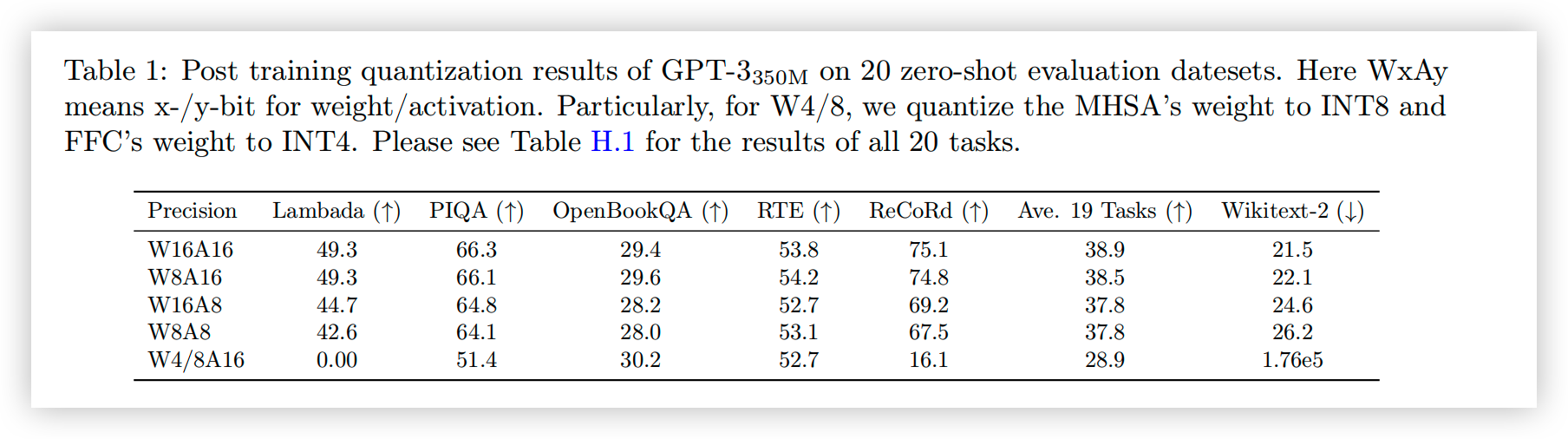
可以看到,INT8 激活量化带来了主要的精度损失,而 weight 量化会导致生成式任务的性能变差。(但 zero-shot 对此不敏感)
为什么 INT8 量化会导致精度损失呢?
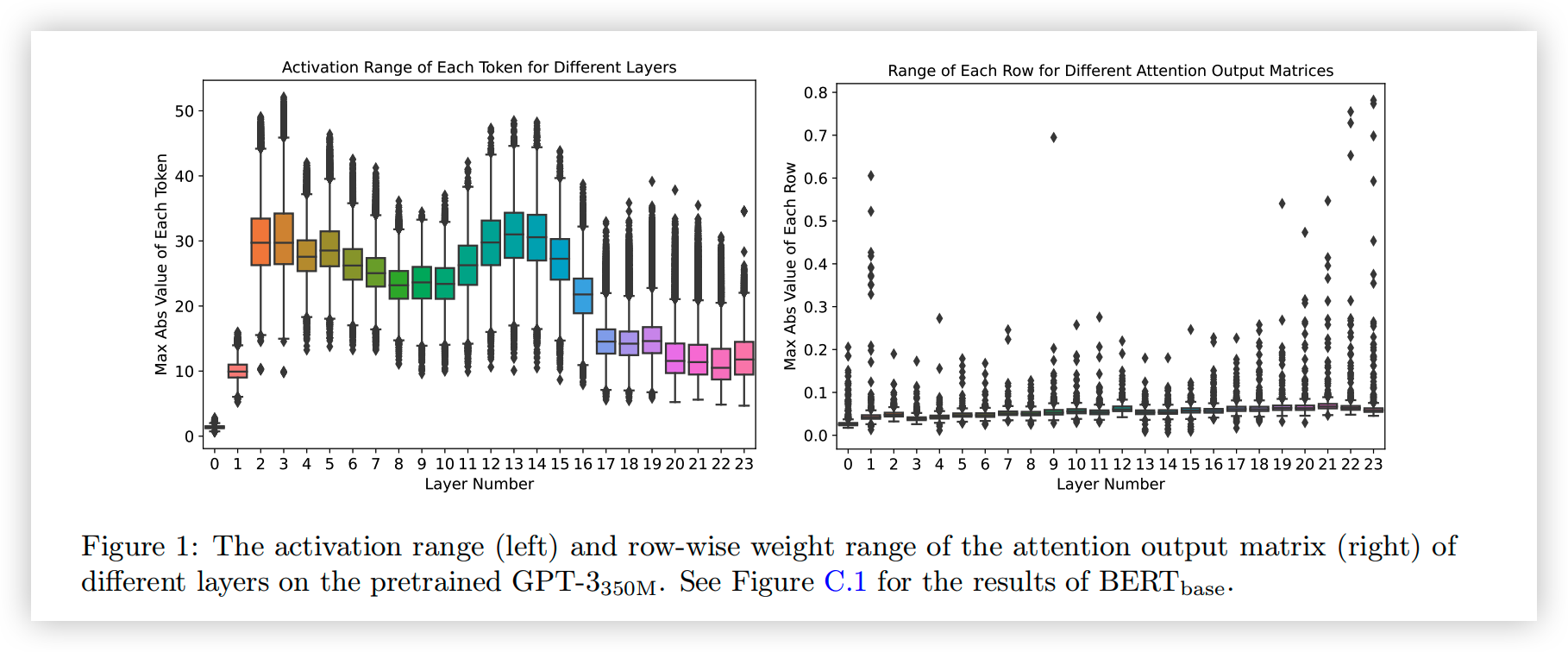
- 激活层的 range 是动态变化的,左图显示了对不同 token 而言,激活层输出的 range 有非常大的差异。譬如说 layer11,最小的 range 为 8,最大的 range 为 35。如果对所有 token 使用相同的量化范围的话,range 较小的 token 就会损失很多精度。
- Weight 中不同行的 range 差距极大。如右图所示,不同行的 range 之间最多有十倍的差距,但是 PTQ 对整个 Weight Matrix 是一起量化的,取的是整个 Weight 的范围。导致 PTQ 的性能较差。如果使用 INT4 量化(总共 16 个数),那对于 range 较小的行,可能只有 2-3 个数的表示范围。
Methodology
为此,Paper 提出了以下几个技术:
Group-wise Quantization for Weights:
- 将权重矩阵划分为多个组,每个组分别量化。
- 针对 GPU 做了优化,降低了推理延迟。

Token-wise Quantization for Activations
- PTQ 一般是静态量化激活的。譬如说离线校准时计算出激活层范围。但是,对于大模型而言,不同 token 的激活范围差异极大,统一静态的量化会导致极大的精度损失。
- 自然的想法是使用更细粒度的量化策略。这篇 paper 提出了逐 token 量化的技术,动态计算每个 token 的激活值范围,再做量化。
- 消除了激活范围校准的开销。
- 但是,逐 token 量化会引入显著的量化和反量化成本,为此,paper 设计了一个高度优化的推理后端。
Quantization-Optimized Transformer Kernels
- 在推理过程中,batch-size 较小,因此推理的延迟主要是 device 和 host 之间的内存搬运导致的。
- 量化本身降低了模型的大小,减少了加载的数据量。但是,量化和反量化运算又导致了额外的开销。
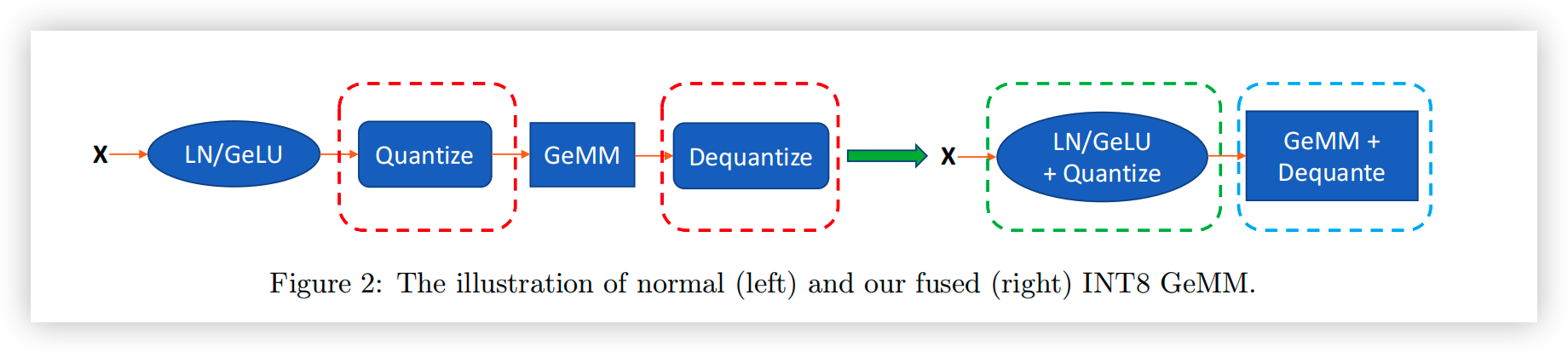
- 使用 CUTLASS INT8 GeMM(通用矩阵乘)。适配 INT8 计算和 kernel fuse。
- Fusing Token-wise Activation Quantization。使用 kernel fuse 技术,将 Activation 的量化操作与之前的运算融合为一个运算,将反量化与 GeMM 融合为一个运算,由于融合的运算使用的是相同的数据,因此规避了量化/反量化带来的额外内存搬运开销。
Layer-by-layer knowledge distillation (LKD)
- 知识蒸馏可以有效降低量化导致的精度损失。
- 但是,知识蒸馏会极大增加内存和计算成本,而且往往需要原始训练数据(经常拿不到)。
所以,paper 提出了逐层蒸馏技术。假设目标模型有 \(N\) 个 transformer 块 \(L_1,L_2,\dots L_N\),数据集为 \((X,Y)\),可以是原始训练数据,也可以来自其他地方。
LKD 使用未量化的模型作为教师模型。若 \(L_k\) 被量化,其量化后的版本为 \(\hat{L_k}\)。那么用 \(L_{k-1}\) 的输出来作为 \(L_k,\hat{L_k}\)的输入,度量学生模型和教师模型的差距,然后更新 \(L_k\)。具体就像这个公式一样。
\[\mathcal{L}_{LKD,k}=MSE(L_k(L_{k-1}(...L_1(X)...))-\hat{L_k}(L_{k-1}(...L_1(X)...)))\]
这么做带来了以下好处:
- LKD 不需要额外的教师模型,而且学生和教师模型共享 L1-Lk-1,其运算结果在之前的迭代中以及知道了,所以额外的运算成本只有 Lk(类似动态规划)。
- 唯一需要 optimize 的层是 Lk,所以只要将 Lk 加载进内存。
- LKD 是逐层优化的,并不优化端到端的模型,所以 LKD 不依赖于原始数据。
Results
- ZeroQuant 可以将 BERT 和 类GPT-3 等模型的权重和激活精度降低到 INT8,对模型准确率的影响最小,同时,与 FP16 推理相比,这些模型的推理速度提高了 5.19 倍/4.16 倍;
- ZeroQuant 加上 LKD 可将全连接模块中的权重量化为 INT4,以及注意力模块中的INT8权重和INT8激活,与FP16模型相比,内存占用减少了3倍;
- ZeroQuant可以直接应用于GPT-J和GPT-NeoX等,其中我们的INT8模型达到了与FP16模型相似的精度,但效率提高了5.2倍。
Reference
- ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers, https://arxiv.org/abs/2206.01861.
- ZeroQuant vedio&slides, https://slideslive.com/38991484/zeroquant-efficient-and-affordable-posttraining-quantization-for-largescale-transformers.
- A Survey on Model Compression for Large Language Models, https://arxiv.org/abs/2308.07633.
- 大模型压缩首篇综述来啦~, https://zhuanlan.zhihu.com/p/652434165.
- 量化感知训练(Quantization-aware-training)探索-从原理到实践, https://zhuanlan.zhihu.com/p/548174416.
- 目前针对大模型进行量化的方法有哪些?, https://www.zhihu.com/question/627484732/answer/3261671478.
- 大模型量化技术原理-ZeroQuant系列, https://zhuanlan.zhihu.com/p/683813769