Distilling Step-by-Step!
Background Knowledge
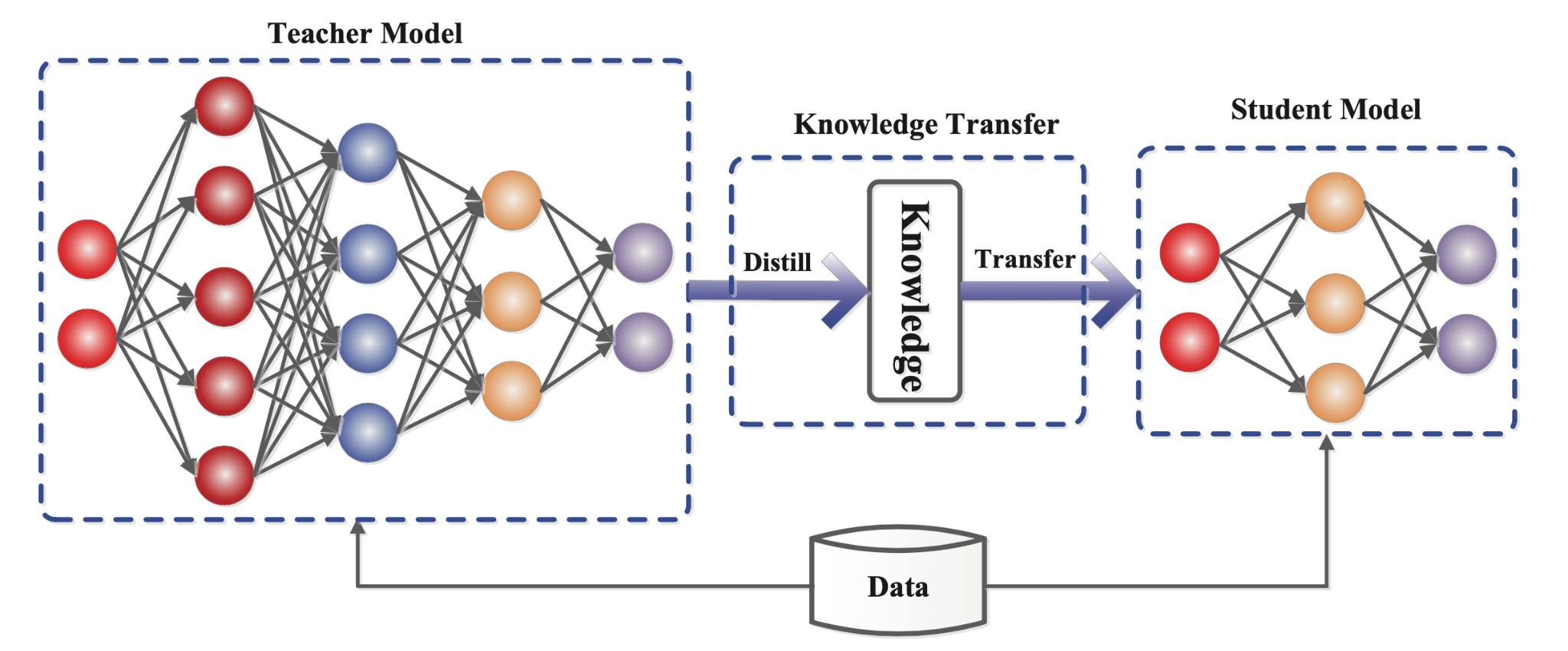
Knowledge Distillation
Knowledge Distillation, 知识蒸馏,是一种模型压缩技术。
如图所示,一个小的 student model 模仿一个大的 teacher model,利用 teacher model 所蕴含的知识获得相似或更高的准确度。
我们可以利用这种技术,将大模型压缩为可以灵活部署的小模型。
CoT(Chain of Thought)
CoT,思维链。
就是说让大模型逐步将一个复杂问题分解为子问题并依次求解,可以显著提升模型的性能。
传统的 prompt 产生的是 input->output 的,但 CoT prompt 生成的是 input->reasoning chain->output。在 CoT 的过程中,会强迫大模型完成推理,在一系列大模型本来就蕴含的知识之间搭起桥梁,起到激活/串联的效果。
典型的,在指令中加上 "Let's think step by step" 就可以唤醒大模型的推理能力。这就是 "Zero-Shot CoT"。
如果在 prompt 中加上示例,用于指定大模型输入输出的格式,则是 "Few-Shot CoT"。
Challenge and Motivation
大模型的部署需要庞大的内存和算力,往往超出了个人或小团队的承载能力。
因此,从业者会选择部署小规模的专用模型。一般由两种方法来得到这些模型:
- Finetune(微调),通过人工标注的数据来更新预训练的小模型。
- Distillation(蒸馏),喂给 teacher model 未标注数据,teacher model 生成标签,来训练 student model。
但是,finetune 需要昂贵的人工标注数据,而 Distillation 则需要大量的未标注数据,这一般很难拿到。

因此,这篇 paper 提出了一种用较少的数据来训练小模型的机制。
Methodology
Inspiration
解决上述问题的灵感来自于 CoT(思维链)。
大模型在推理时可以生成一系列的中间步骤(rationales),用于解释最终的输出,我们可以提取这些中间步骤,用于小模型的训练。
给个例子。
问题:有一个长为 15m,宽为 11m 的房间,其中 16 平米已经铺了地砖,请问还要铺多少平米的地砖?
中间步骤:面积=长 * 宽,这个房间的面积是 15x11 平米。
答案:(11x15)-16。
中间步骤会提供更多的额外信息,譬如说面积的计算公式,以往这些信息一般需要更多的数据才能被小模型学会。
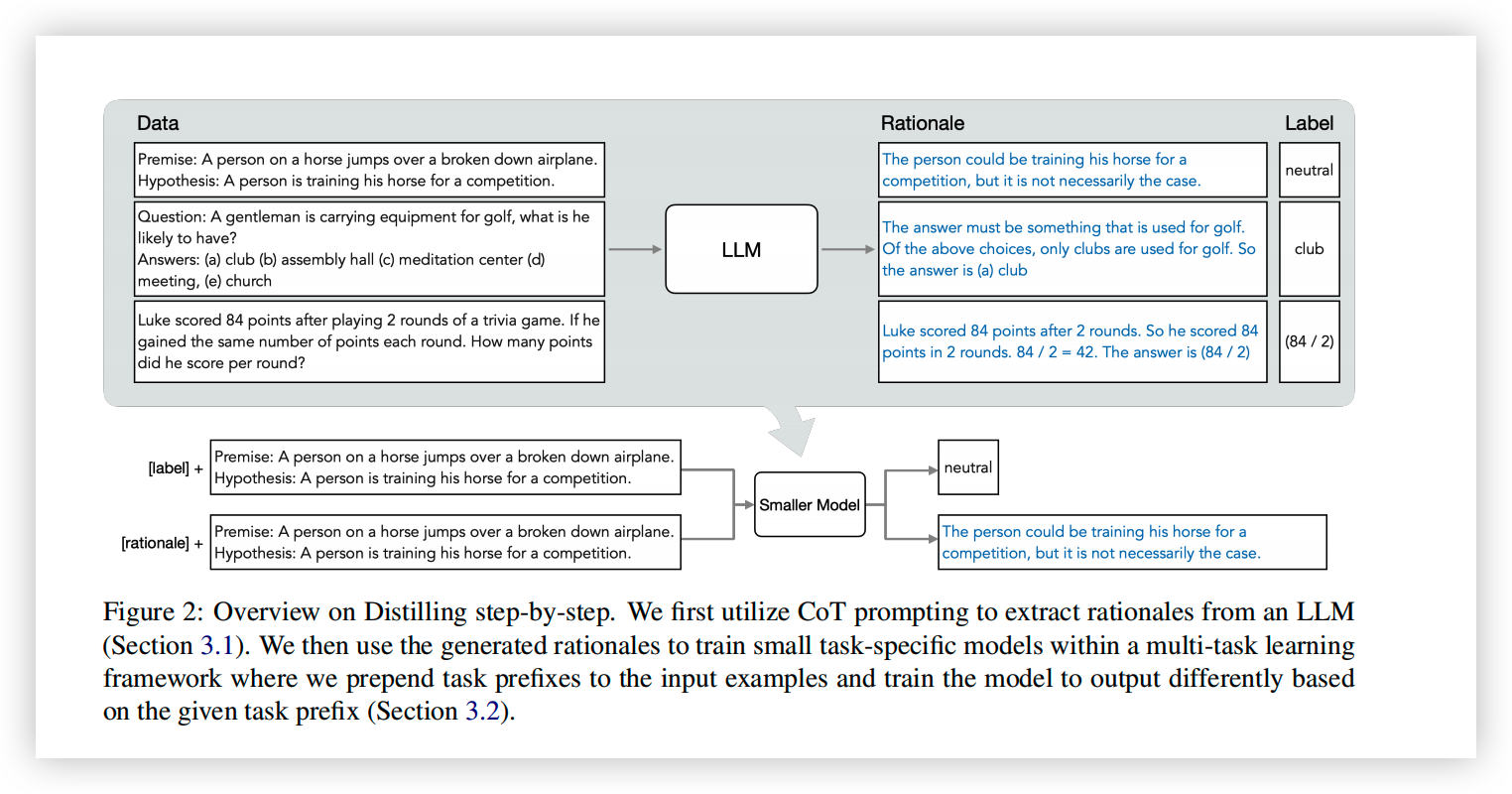
Extracting Rationales(Generate Dataset)
首先需要通过未标注的数据和大模型,得到训练小模型要用的数据(包含 rationale/label)。
这一步很简单,通过在输入前添加 prompt 实现。
prompt 是一个输入输出的样例,包含样例输入,样例输出和 rantionales,告诉大模型需要在生成结果的同时生成 rationales。

形式化一下:
- Unlabled dataset: \(D_{unlabled}=\{x_i\}\)
- Prompt triplet: \(P=(x^P,r^P,y^P)\)
- LLM output: \((\hat{y_i},\hat{r_i})=LLM(x_i,P)\)
- Training dataset: \(D=\{(x_i,\hat{y_i},\hat{r_i})\}\)
- Small model: \(f\)
Training smaller models with rationales
一般的,如果不使用 rationales,那么蒸馏使用 LLM 生成的 label 来作为训练 label。
\[\mathcal{L}_{label}=\frac{1}{N}\sum_{i=1}^N l(f(x_i),\hat{y_i})\]
但是,怎么把 rationales 加进 training 过程中呢?
一种直接的思路是将 rationales 作为小模型的额外输入来训练,最近的一些工作就是这么做的。
\[f(x_i,\hat{r_i})\rightarrow \hat{y_i}\]
\[\mathcal{L}=\frac{1}{N}\sum_{i=1}^N l(f(x_i,\hat{r_i}),\hat{y_i})\]
但是,因为小模型需要额外的 rationales 作为输入,所以在推理时大模型仍然是必要的,因为需要先通过大模型生成 rationales,小模型才能产生输出。这与知识蒸馏的初衷背道而驰,因为大模型在部署时仍然是必要的。
因此,这篇 paper 采用了另外一种方法,使小模型同时输出 label 和 rationales。在输入前添加前缀 [lable]/[rationale],当前缀为 [lable] 时输出 \(y_i\),前缀为 [rationale] 时输出 \(r_i\)。损失函数则是两者的加权。
\[f(x_i)\rightarrow (y_i,r_i)\] \[\mathcal{L}_{rationale}=\frac{1}{N}\sum_{i=1}^N l(f(x_i),\hat{r_i})\] \[\mathcal{L}=\mathcal{L}_{lable}+\lambda \mathcal{L}_{rationale}\]
与之前的方法相比,小模型部署时不再依赖大模型。并且在训练中学习到了大模型的中间推理步骤。
Results
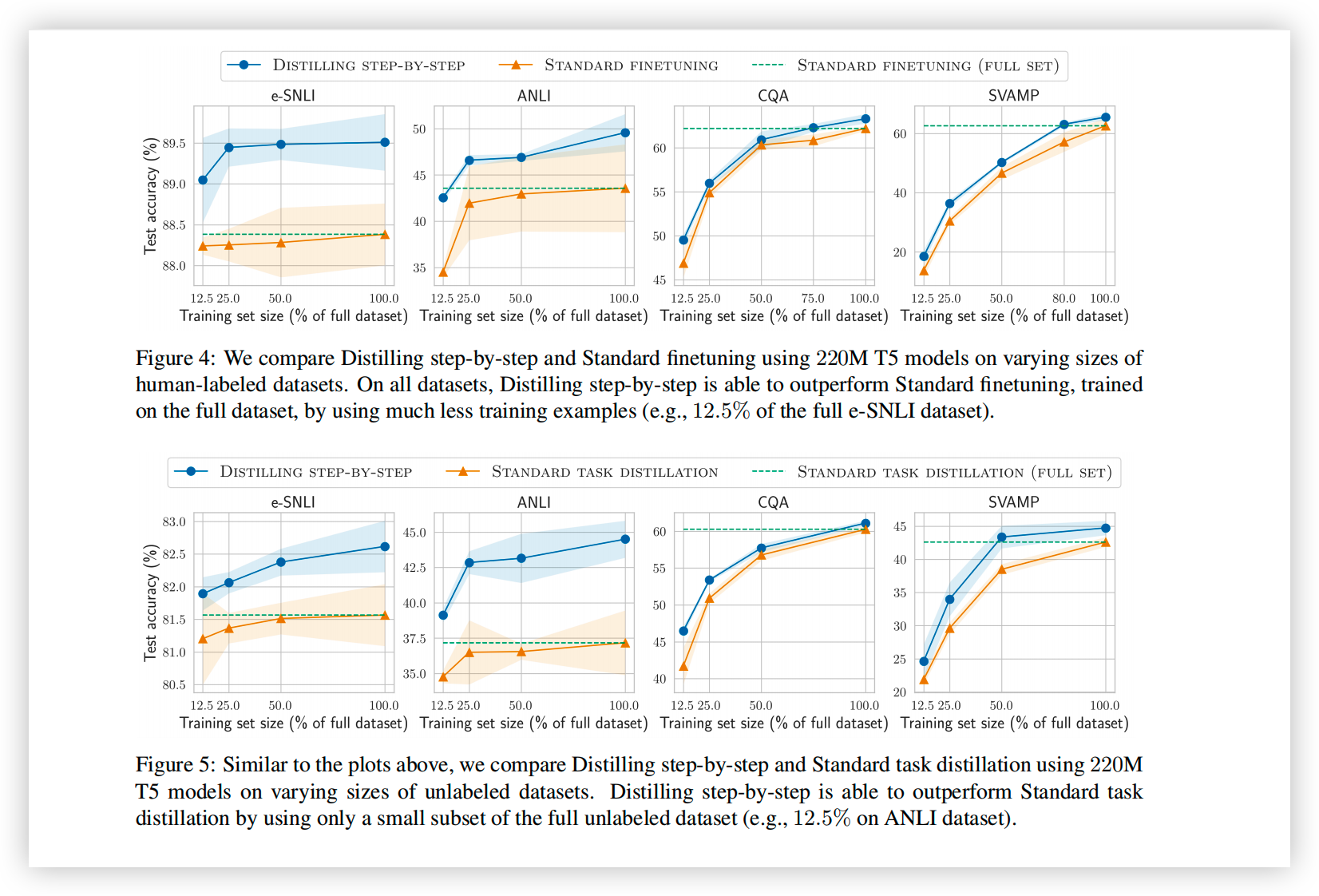
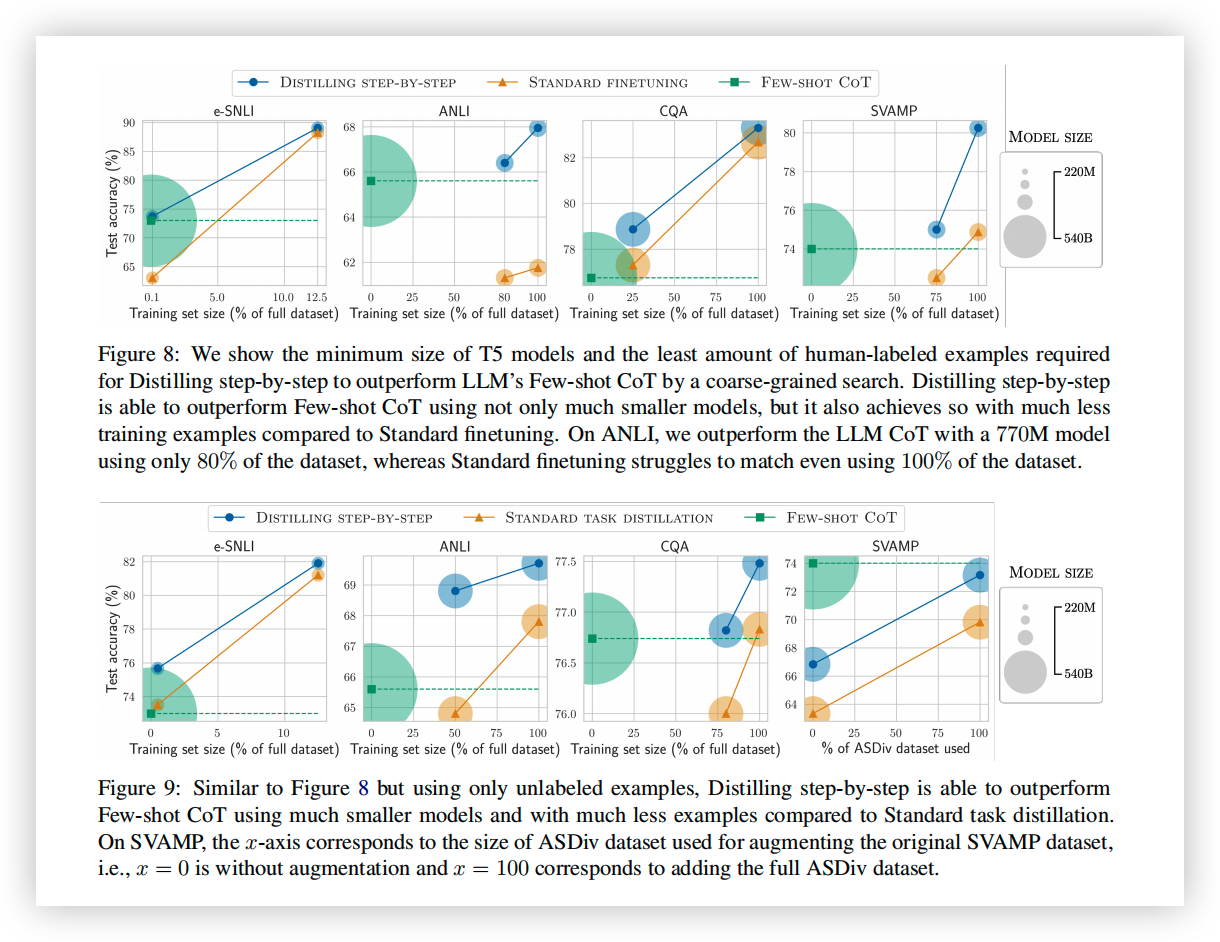
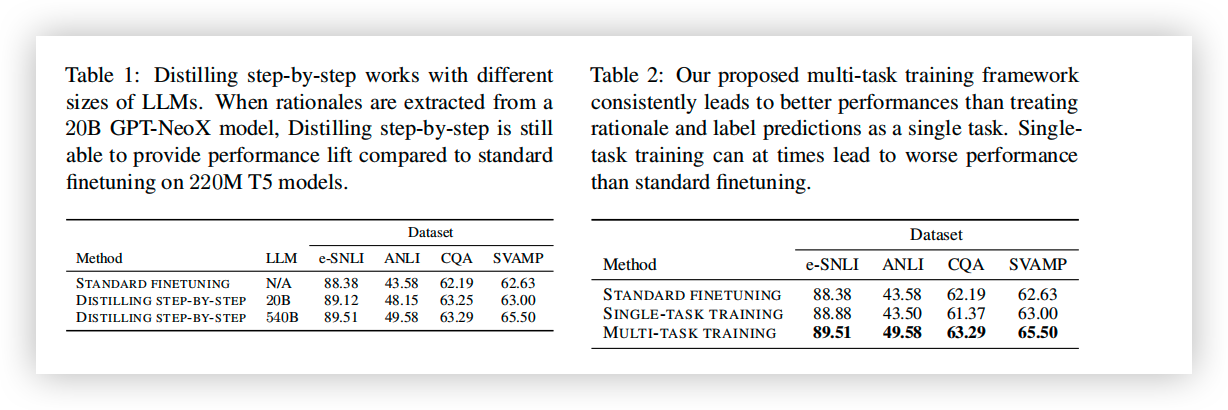
- 与传统的 finetune/KD 相比,上述方法可以在仅使用 15%-50% 的训练数据的情况下,达到更好的性能。
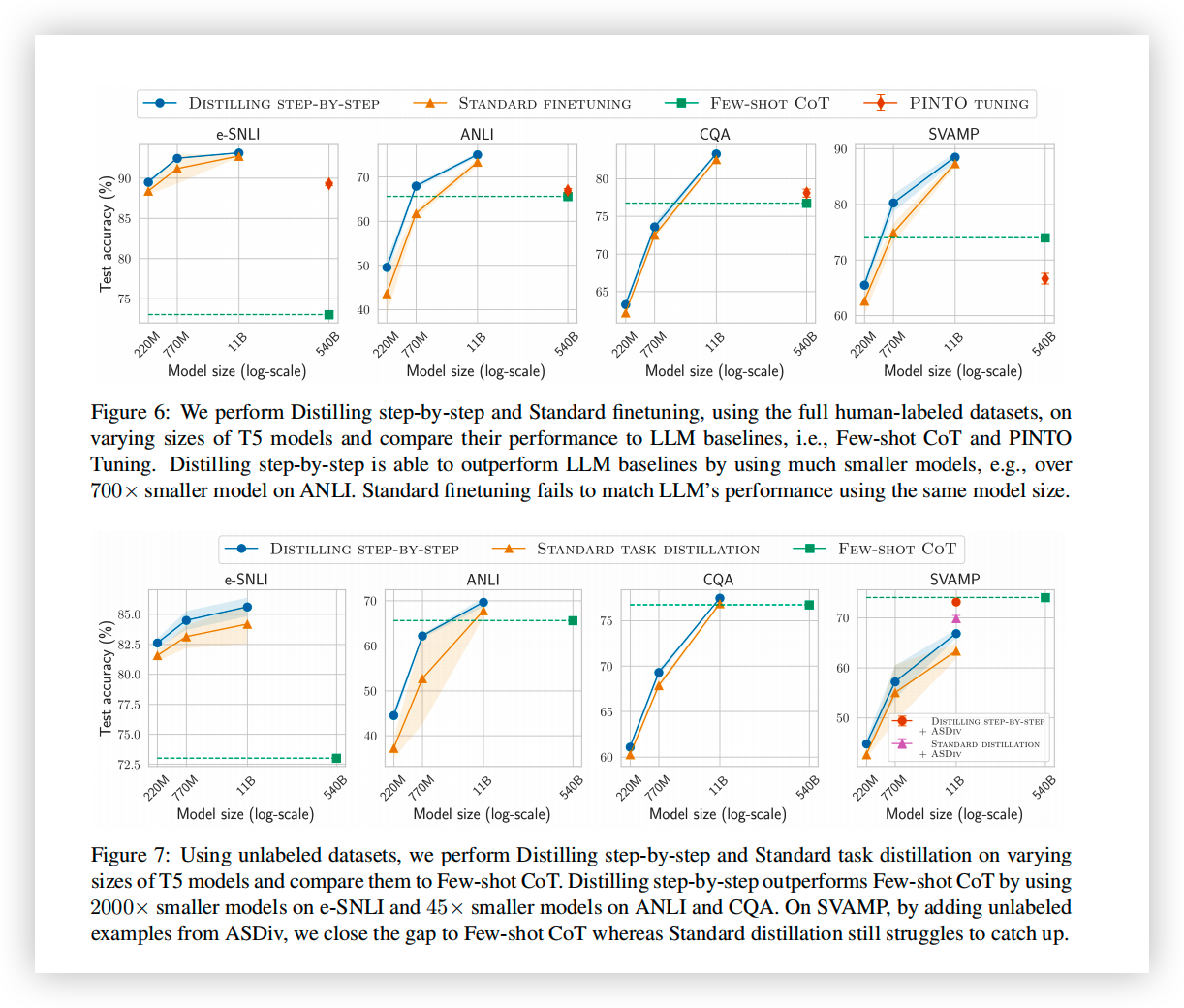
- 与 LLM 相比,可以用更小的模型大小(最小是 LLM 的 1/2000)取得比 LLM 更好的表现。
- 使用了更少的数据和更小的模型,在性能上超越了 LLM。
Reference
- Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes, https://arxiv.org/abs/2305.02301.
- A Survey on Knowledge Distillation of Large Language Model, https://arxiv.org/abs/2402.13116.
- A Survey on Model Compression for Large Language Models, https://arxiv.org/abs/2308.07633.
- 一文读懂:大模型思维链 CoT(Chain of Thought), https://zhuanlan.zhihu.com/p/670907685.
- 知识蒸馏:原理、算法、应用, https://zhuanlan.zhihu.com/p/637108617.
- 论文笔记(LLM+蒸馏):Distilling step-by-step+代码分析, https://zhuanlan.zhihu.com/p/642300072.
- 大规模语言模型知识蒸馏综述 https://zhuanlan.zhihu.com/p/695640168.